 Elasticsearch基础入门
Elasticsearch基础入门
关于Elasticsearch
ElasticSearch(简称ES)是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。--来自百度百科
ES是如何产生的?
1. 大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
- 用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
- 如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
- 如何保证数据安全性;(热备、冷备、异地多活)
- 如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
- 如何解决统计分析问题;(离线、近实时)
2. 传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈,解决要点:
- 通过主从备份解决数据安全性问题;
- 通过数据库代理中间件心跳监测,解决单点故障问题;
- 通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果

3. 非关系型数据库的解决方案
- 通过副本备份保证数据安全性;
- 通过节点竞选机制解决单点问题;
- 先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
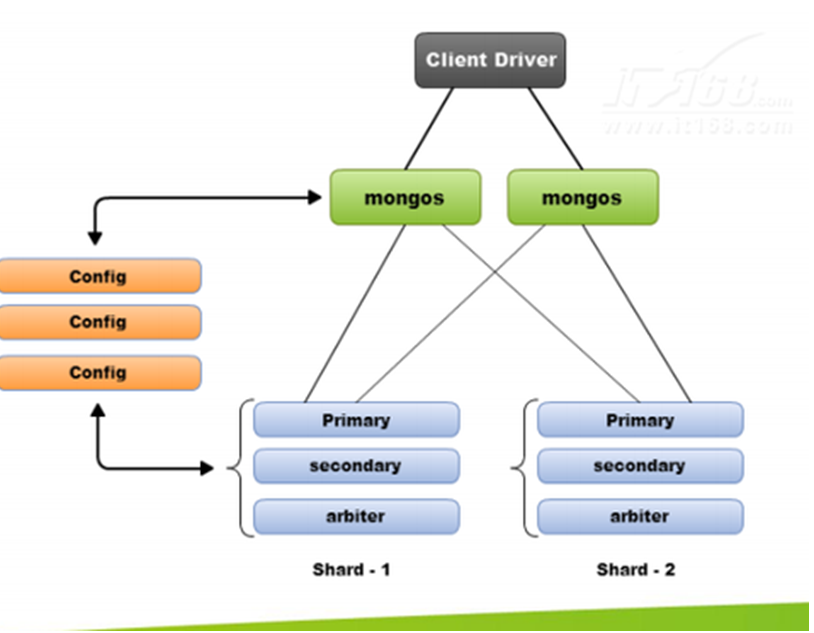
ES主要解决什么问题?
- 检索相关数据
- 返回统计结果
- 速度快
ES工作原理
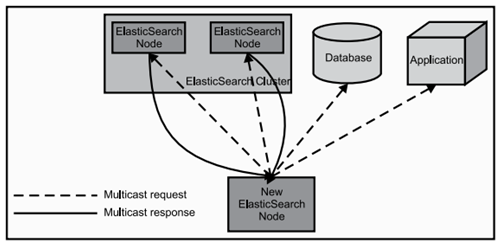
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
ES核心概念
1. Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2. Node:节点
形成集群的每个服务器称为节点。
3. Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4. Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5. 全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于mysql里的like语句。全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
ES数据架构与关系型数据库MYSQL对比
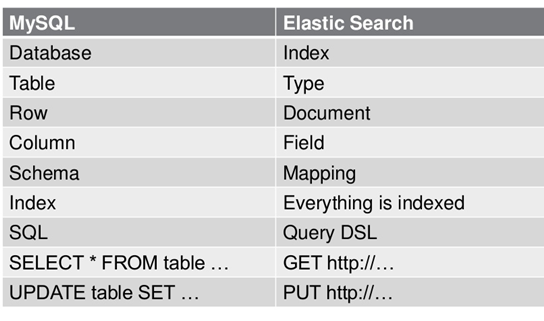
- 关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)。
- 一个数据库下面有N张表(Table),等价于1个索引Index下面有N多类型(Type)。
- 一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
- 在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
- 在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT/POST、删Delete、改_update、查GET.
ELK是什么?
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
ES特点和优势
- 分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
- 实时分析的分布式搜索引擎。
分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作;负载再平衡和路由在大多数情况下自动完成。 - 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上
- 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
安装部署ES(Linux Or MAC OS)
二进制安装
- 零配置,开箱即用
- 没有繁琐的安装配置
- java版本要求:最低1.7
echo $JAVA_HOME
/opt/jdk1.8.0_91
下载地址:传送门
启动
tar -xzvf elasticsearch-6.2.4.tar.gz
cd elasticsearch-6.2.4
./bin/elasticsearch
# 后台运行
bin/elasticsearch -d
centos7使用二进制安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-7.12.0-linux-x86_64.tar.gz.sha512
tar -xvf elasticsearch-7.12.0-linux-x86_64.tar.gz -C /usr/share/elasticsearch-7.12.0
cd elasticsearch-7.12.0/
# 安装es中文分词插件
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.0/elasticsearch-analysis-ik-7.12.0.zip
docker安装
docker run -d --name=elasticsearch --restart=always \
-p 0.0.0.0:9200:9200 \
-p 0.0.0.0:9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v data/elasticsearch/data:/usr/share/elasticsearch/data \
-v /data/elasticsearch/logs:/usr/share/elasticsearch/logs \
docker.elastic.co/elasticsearch/elasticsearch:7.12.0
ES必要的插件
必要的Head、kibana、IK(中文分词)、pinyin(拼音)、graph等插件的详细安装和使用。传送门
ES接口使用
常见的增、删、改、查操作:传送门